


13.8和13.11哪个大?大模型竟然开始“一本正经地胡说八道”……
 图说:不同大模型回答“13.8和13.11哪个大?”
图说:不同大模型回答“13.8和13.11哪个大?”13.8和13.11哪个大?
综艺节目的选手排名,竟让一道本不该成为争议的“小学数学题”,在网上掀起讨论。
不仅部分人类搞不清楚,“聪明”的大模型也洋相百出——简单的常识题对它们来说还是有难度!
记者测试了多款大模型,在这道数学题上,它们错得“振振有词”。
错得“各有千秋”
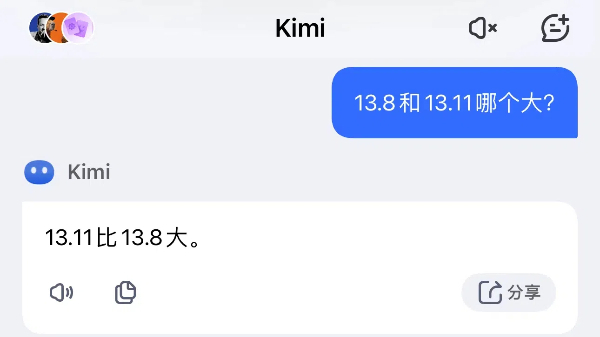
在2024世界人工智能大会上惊艳亮相的阶跃星辰,其产品“跃问”就在这道题上栽了跟头——
“比较两个数的大小,可以直接观察它们的十位和小数部分”,这句判断,就已经忘了个位数的存在。
“由于十位相同,我们只需要比较小数部分。0.11等于11/100,而0.8等于8/100。显然,11/100大于8/100,所以13.11大于13.8。”相信明眼人一眼就看出了大模型的“故障”所在。
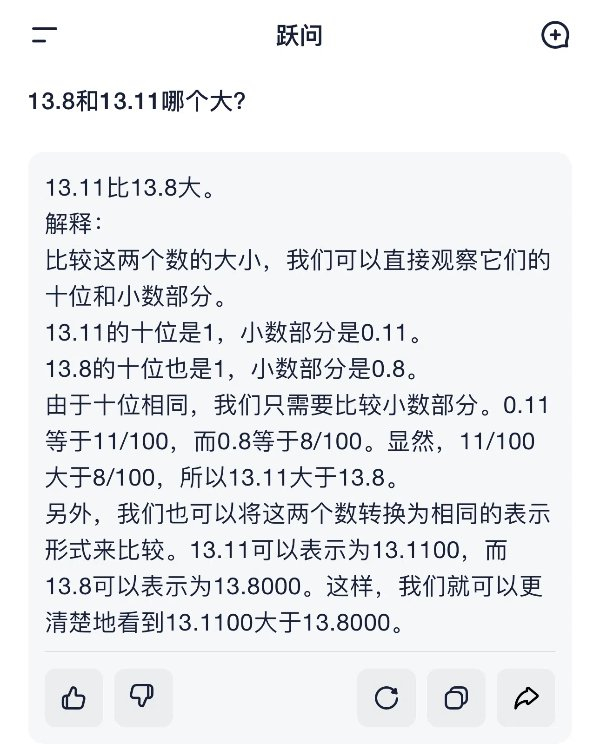
已经被不少人广泛使用的月之暗面kimi,同样回答错误。面对相同的问题,它“斩钉截铁”:13.11比13.8大。再追问为什么,kimi认为先比较整数部分,两者相等。接下去就让人越来越看不懂,“然后比较十分位上的数字,两者都是8……接下来比较百分位上的数字,13.8的百分位是0,而13.11的百分位是1。由于1大于0,因此百分位上13.11更大。”
用大家熟悉的话来评价就是——一本正经地胡说八道。
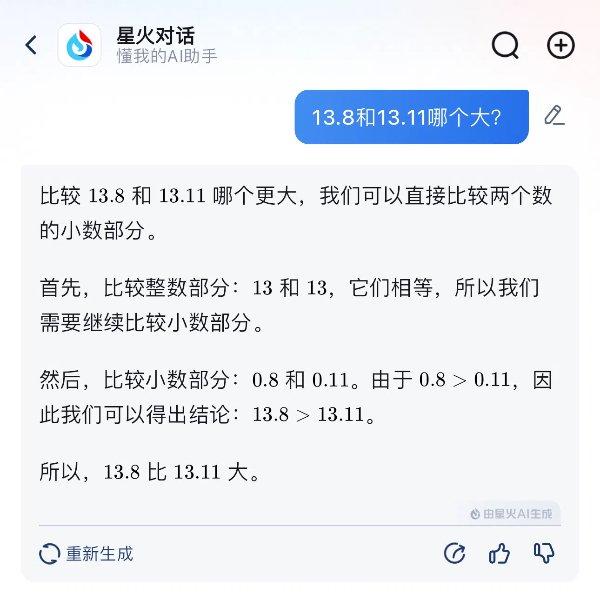
科大讯飞的“星火”,是回答正确的“选手”之一。在最关键的步骤,“星火”判断:小数部分0.8大于0.11,因此可以得出13.8大于13.11的结论。
常识推理仍需学习
多家大模型研发企业的研发人员解释称,两个数字的大小比较对于普通人来说是常识,然而对大模型而言,它们并不能理解这两个数字是什么意思。如果明确告知大模型两个数字是浮点数(实数)再让其比较的话,大模型就更容易理解这个问题的内涵。
换种简单的说法,在软件版号迭代、文件系统中,13.11都是在13.8之后的;如果整数部分小于等于12,从日期来看,12.11也是在12.8之后。“大模型采用的是token(词元) by token生成预测的方式,所以大模型会把13.11会拆解成13,.(点)和11三部分,并以同样方式拆解13.8,所以在比较时会出现错误。”有研发人员表示。
在他们看来,这一现象也反映了大模型和人类认知的差异:大模型是基于统计模型和模式识别,而不像人类基于逻辑推理和概念理解。
“虽然大模型在很多方面的能力都非常强悍,但在常识推理能力上还需要持续学习进步。”科大讯飞研发人员说。
数理推理能力有短板
继公布AI高考语数外成绩后,由上海人工智能实验室推出的大模型开源开放评测体系“司南”又在近日对7款大模型进行了高考全科目测试。结果显示,在理科成绩方面,“AI考生”整体弱于文科,体现了大模型在数理推理能力上普遍存在短板。
在数学科目的一道题目中,大模型由于在解题过程中出现了计算错误,导致不正确的求k值方程式出现。面对非常复杂难解的方程式,模型依然选择“硬解”,还直接蒙了一个答案——该答案无法使等式成立。
阅卷教师指出,对于大多数人类考生,一旦发现计算存在问题,会反思此前的步骤并重新更正计算过程,而不会“硬蒙”出答案。
同样在数学科目的一道立体几何题中,大模型的平均得分率为8.5%,远低于数学科目平均得分率35.5%,通过检查模型回答,评测团队发现,模型往往会出现一些完全不符合空间逻辑的推断。
“当前大模型仍存在很大的局限性。组织大模型‘参加高考’,目的是评测当前大模型的真实水平,找准问题,持续推进技术进步。”司南相关负责人介绍。
新民晚报记者 郜阳
【更多阅读】语文能考124分 数学都不及格……这群“偏科”的考生是谁?阅卷老师这么说
- 2 首发!手机上能用的免费AI视频工具,文案一键生成原创视频!
- 3 “NFT”骗局还是游戏?《香蕉》同时在线“人”数超50万
- 4 德州市自然资源局干部职工成为短视频主角 让政策宣传更接地气没想到,央视主持人桑晨原来是这位大明星的后代,难怪长这么好看
- 5 被抖音限流 美妆品牌温博士销售额断崖式下滑初中生作文引用“原神”,老师看完沉默了,网友:隔着屏幕都尴尬
- 6 争议中的数字人直播上海地铁上两名男子不雅举动,视频曝光,丝毫不顾周围乘客的感受
- 7 京东管理人员名单 京东高层管理人员 京东高层领导简历
- 8 吉利银河星舰内饰发布:首搭AI智能座椅
- 9 微信:9月1日起,微信小程序须完成备案后才可上架
- 10 一款免费无限制的AI视频生成工具火了!国内无障碍访问!附教程
- 11 《香蕉》NFT游戏引争议:同时在线玩家数突破50万






- 聊聊我喜欢的10个优质,正能量的自媒体
- 首发!手机上能用的免费AI视频工具,文案一键生成原创视频!
- “NFT”骗局还是游戏?《香蕉》同时在线“人”数超50万
- 德州市自然资源局干部职工成为短视频主角 让政策宣传更接地气没想到,央视主持人桑晨原来是这位大明星的后代,难怪长这么好看
- 被抖音限流 美妆品牌温博士销售额断崖式下滑初中生作文引用“原神”,老师看完沉默了,网友:隔着屏幕都尴尬
- 争议中的数字人直播上海地铁上两名男子不雅举动,视频曝光,丝毫不顾周围乘客的感受
- 京东管理人员名单 京东高层管理人员 京东高层领导简历
- 吉利银河星舰内饰发布:首搭AI智能座椅
- 微信:9月1日起,微信小程序须完成备案后才可上架
- 一款免费无限制的AI视频生成工具火了!国内无障碍访问!附教程
- 《香蕉》NFT游戏引争议:同时在线玩家数突破50万
- 调查报道|长沙一小区物业费收3.98元/㎡/月 监管:未备案,已责令整
- 高盛:重申阿里健康(00241)“买入”评级 目标价4.4港元
- 大健康是什么意思
- 快手管理层有谁?快手领导班子名单 快手主要领导简介
